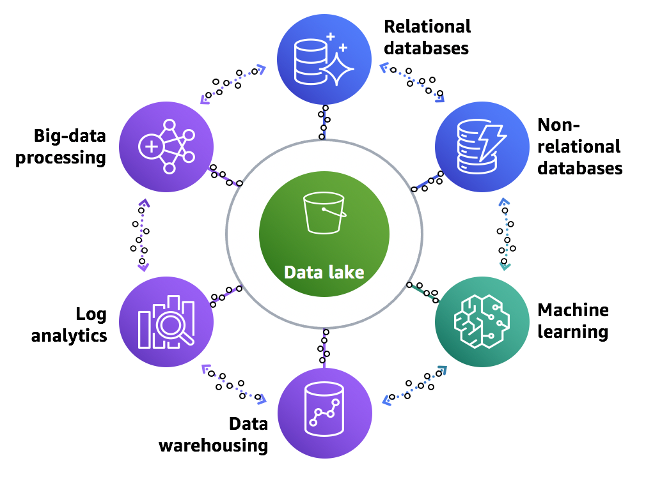
Discerning business leaders recognize data’s role in driving growth and competitive edge. By Utilizing Lake House Architecture, you can access a consolidated data view, expedite new data onboarding, and distribute analytics throughout your enterprise. This article offers an overview of AWS Lake House Architecture and its impact on businesses.
Lake House Architecture Explained
The Lake House Architecture is a modern data infrastructure that unifies data lakes and data warehouses at the storage and catalog levels. AWS implementation eliminates the need to move data between these systems, accelerating data processing by avoiding redundant data movement, duplication, and ETL code.
Lake House Architecture in Action
The data warehouse and data lake are natively integrated at storage and catalog layers, presenting a unified Lake House interface for processing and consumption layers. Components of these layers, such as SQL or Spark, can access data stored in the Lake House storage layer, covering both the data warehouse and data lake. Native ETL or ELT pipelines in the data warehouse can merge flat relational data with complex, hierarchical structured data in the data lake.
Deep dive into Lake House architecture layers on AWS

Data Ingestion Layer is responsible for collecting and ingesting data from various sources, such as databases, applications, and IoT devices, into the Lake House system. AWS offers a range of services for data ingestion, including Amazon Kinesis for streaming data and Amazon MWAA(Apache Airflow) for batch processing. These tools enable seamless data integration while ensuring data consistency, security, and privacy.
The Catalog Layer serves as the central metadata repository for all data stored in the Lake House. It maintains schema definitions, data lineage, and other metadata for seamless data discovery and governance. AWS Glue Catalog, a managed data catalog service, integrates with other AWS services such as Amazon S3, Amazon Redshift, and Amazon Athena to provide a unified catalog for your data lake and data warehouse.
The Data Processing Layer is responsible for transforming, cleaning, and enriching data to make it suitable for analysis. AWS offers a wide range of tools to process data in the Lake House. For instance, AWS Glue for serverless data processing, Amazon EMR for big data processing with Apache Spark, and Amazon Redshift for data warehousing tasks. These services facilitate efficient data processing, enabling you to derive valuable insights from your data.
Data Consumption Layer encompasses tools and services that allow users to access, analyze, and visualize data stored in the Lake House. AWS provides various data consumption tools, such as Amazon Athena for serverless querying, Amazon Redshift Spectrum for extending data warehouse queries to the data lake, and Amazon QuickSight for creating interactive BI dashboards. These services empower different personas within an organization to access and analyze data, promoting data-driven decision-making across the enterprise.
By leveraging these layers within the Lake House Architecture organizations can create a robust, scalable, and cost-effective data management solution that unlocks the full potential of their data.
As always, for any data platform needs, contact us at DataPhoenix — small end-to-end data solutions.