Overview
This guide aims to empower you with the fundamental knowledge needed to understand what a standard data lake is, it’s main architecture elements and how you can utilise AWS services for managing your data securely and effectively. With base-level understanding, you can build your expertise in data lakes and implement them across various business functions.
About authors
DataPhoenix provides consulting and professional services focused on delivery of data management platforms in AWS. Based on our in depth experience delivering data platforms to small business and large enterprise we present you “The Definitive Guide to Data Lakes”, a comprehensive resource for decision-makers, CTOs , Data Architects and Engineers. Delve into the world of Data Lakes and understand technical aspects, as well as business benefits.
Index
What is a data lake
Picture yourself working at a company, serving as the system administrator. Your primary responsibility is to ensure that everything runs seamlessly without any hitches. The company delegates tasks among smaller teams, each overseeing a different aspect, such as code development, project management, or database modelling. However, you soon encounter a problem: customers are complaining about slow system performance. Upon investigation, you realise that the database is nearing its capacity and is being used for all functions. It becomes apparent that a “one size fits all” approach is inappropriate. To address this issue, you need to segregate the data into separate components, allowing for more strategic administration.
A data lake serves as the solution to challenges arising from traditional database and data processing techniques, offering a superior approach for modern workloads.
If you find yourself in a similar situation, a data lake could be immensely beneficial. Cloud-based data lake services like AWS can handle storage, analytics, real-time analysis, and machine learning separately.
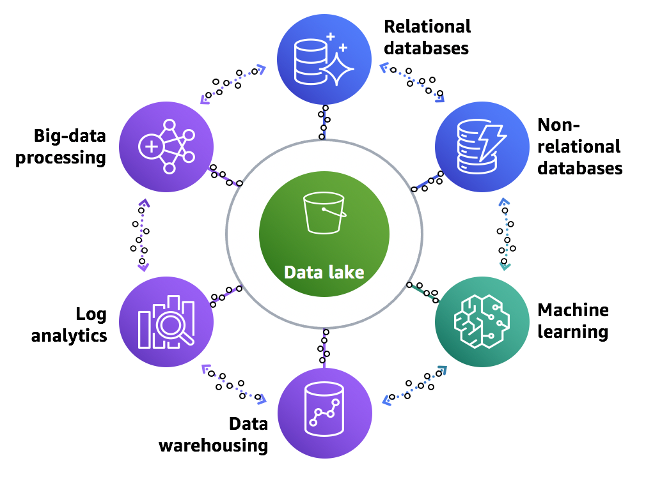
In essence, a data lake is an intelligent storage system capable of accommodating any business-related data, both structured and unstructured, directly from its source.
Why use a data Lake
Progressive businesses employ data lakes to leverage their data and outshine competitors. Pairing data lakes with machine learning solutions and in-depth analytics, they reap a wide array of benefits. The flexibility of AWS services enables businesses to attain their unique objectives. Insights gleaned from AWS Data Lakes can aid in decision-making, operational efficiency, cost reduction, proactive maintenance, productivity enhancement, research, customer retention, and more. Consequently, AWS data lakes can enhance your company’s efficiency in handling database workloads and reduce transactional costs.
Even if you’re unsure about how or when to use specific unstructured data, data lakes offer an inexpensive and secure storage solution. Businesses can extract insights from their data lakes whenever they’re ready, providing a considerable advantage over traditional databases that discard data if not needed immediately and unlike data warehouses storing data in data lake is much more cost effective. This future-proofs your business without hindering access to vital business data. The data can be accumulated over months and analysed when a business case arises.
Another significant benefit of data lakes is their flexibility. Traditional databases often comprise multiple mechanisms and properties, which can pose challenges for platforms that require specific structures to process the data. In contrast, data lakes can store data without processing or altering the structure of the information (decoupling).
Furthermore, data lakes enable secure storage of both structured and unstructured data without scaling limitations. This advantage can save considerable time and effort that would otherwise be spent sorting out different data structures for the computer to process.
The term ‘lake’ aptly reflects these benefits, evoking the organic nature of an actual lake.
Characteristics of data lake
A database typically collects only one type of structured data, whereas a data lake is data agnostic, meaning it is not limited to a specific structure, data type, or file size. This includes diverse formats like photos, videos, texts, compressed or encrypted files, and more. The freeform structure of data lakes enables businesses to make swift changes to queries and models, providing a competitive edge. Data lakes facilitate a broader range of analytics compared to traditional databases.
Another crucial characteristic of data lakes is their ability to help with prediction of future outcomes based on historical data. This can help businesses detect market gaps, potential problems, and gain insight into future performance. This future-proofing can offer a significant advantage over competitors. The simplicity and flexibility of data lake infrastructure allow for structural remodelling based on evolving business needs.
Data Lake vs Data Warehouse
A data warehouse is a centralised database that receives input from transactional systems and line-of-business applications and is set up to analyse this data. Data must be curated within data warehouses to fit into tables, which requires cleaning and formatting to facilitate fast SQL queries.
Although this may sound similar to data lakes, there are significant differences. Data warehouses are typically used for analytics and insights, but require defining the structure of your data beforehand. This means they mostly contain structured data, and the structure must be defined before analysis can occur, known as schema-on-write architecture.
Some may prefer this method as a defined structure can identify or reject data anomalies. However, data lakes offer greater flexibility with a schema-on-read architecture, which allows for unstructured data processing. As a result, the quality of analytics varies between data warehouses and data lakes. Data lake analysis includes big data analytics, full-text search, real-time analytics, and machine learning, all of which can reveal valuable business insights.
Another difference is that data warehouses primarily use SQL for queries, limiting their flexibility. Data lakes, on the other hand, support a range of tools depending on the service needed. While data warehouses can provide business intelligence, batch reporting, and visualisations, data lakes also offer predictive analytics, data discovery, machine learning, profiling.
Data warehouses typically cater only to business analysts, whereas AWS Data Lakes can support all users. From operations managers needing daily reports to data scientists conducting statistical analysis and predictive modelling, everyone in the business can access the required information from this single repository.
It’s worth noting that the choice between data lakes and data warehouses isn’t always mutually exclusive. Many organisations opt for a combination of the two, which is called a lake house architecture, catering to different needs and uses, and ultimately achieving the biggest success in extracting value from data.
Data lake components on AWS
AWS Services serve as the foundation of a data lake, providing a plethora of options to cater to various needs. These services fall into three primary categories: data storage and organisation, data transfer, and analytics and processing. One of the main advantages of a data lake is its ability to store data on an unlimited scale, addressing any concerns regarding space constraints. Furthermore, data lakes can store both structured and unstructured data using a schema-on-read approach. They also organise data in a manner that readies it for transfer – a critical step for processing and analytics. Lastly, the analytics and processing category encompasses a wide array of services, enabling users to manage multiple databases, generate reports, visualise data, or modify their data structure.
Amazon S3 – data storage
Your business may require a service capable of handling vast amounts of structured and unstructured data. This necessitates a solution that supports schema-on-read and unlimited scaling. Amazon Simple Storage Service (S3), along with S3 Glacier, fits the bill, functioning as the ‘data storage and organisation’ service. It is designed to simplify computing for both you and developers.
A standout feature of S3 is its ability to store any type of data file, be it a video, document, audio file, or a mix of various formats. This data-agnostic approach ensures centralisation and consolidation of data in one location.
Moreover, S3 caters to individual scaling needs, accommodating anything from a few gigabytes to hundreds of terabytes. As your data grows over time, this service adapts accordingly. A key concern for many is the durability of data storage services. S3 boasts an exceptional durability rate of 99.999999999% (more nines than anybody cares to count) annually, making the chances of data loss exceedingly low. Consequently, even if you don’t use the data now, you can safely retrieve it in the future.
S3 also employs a clever storage technique that helps reduce costs. It offers various storage tiers, categorising data based on access frequency. For example, frequently accessed data incurs lower access charges but higher storage costs. Conversely, infrequently accessed data has lower storage costs but higher retrieval fees. Thanks to ‘intelligent cataloguing’, you needn’t worry about organising these tiers, as the system monitors access patterns and manages the data for you. Amazon S3 Glacier and S3 Glacier Deep services cater to rarely accessed data by archiving it, ensuring lower storage costs. However, retrieving this data may be more time-consuming and expensive, which shouldn’t pose an issue if the data is seldom used. More commonly accessed data is placed in the S3 standard tier for easier access.
AWS Glue – data catalog
For businesses struggling to organise vast amounts of data or identify data types and sources, AWS Glue is the ideal solution. AWS Glue is a fully managed, serverless service designed to process and organise data on your behalf. It features an AWS Glue catalog containing tables that help categorise and declutter your data. The ‘glue crawler’ then sorts these tables into the appropriate databases by classifying the data by type, schema, and structure within your S3. While the glue crawler can perform this task automatically, you still have the option to classify data according to your preferences, particularly useful if the crawler cannot recognise certain data structures. As your data evolves over time, the glue crawler continues to update the existing data catalog.
Kinesis – data streaming services
When moving data, the data’s origin and type are crucial factors to consider. The Kinesis family of services provides real-time data ingestion in a reliable, secure, and cost-effective manner at scale. Kinesis Data Streams collect data from all sources, process it, and then move it into another service, such as S3. If you prefer a self-management approach, the Software Development Kit (SDK) is suitable for you. SDK processes data in smaller fragments, giving you control over scaling and data destinations. One advantage of SDK is that multiple people can process the data, allowing you to delegate tasks to colleagues.
If you prefer a more automated approach requiring minimal intervention, Kinesis Firehose is the service for you. Like SDK, Firehose processes data in real-time, with the only aspect requiring management being the data’s destination and storage location. This approach is typically better suited for cases that demand minimal processing before data movement and storage.
Another service to consider is API Gateway. If your data doesn’t require real-time processing, API Gateway could be a more suitable option. By inputting your HTTP source, the data is processed and directed to your data lake. One drawback, however, is that the data may not be ingested as deeply as with the Kinesis family of services. API Gateway offers a simpler approach with fewer features included.
Batch processing data services
Batch processing is a common method for analysing and processing data. It can help identify errors, missing information, or areas for improvement within the data. AWS EMR which is Apache Hadoop managed solution, is a service designed for the efficient analysis and processing of vast amounts of data (even petabytes). It does this by organising a cluster of computers that can coordinate and process data quickly, which is often more efficient and cost-effective than relying on a single supercomputer. EMR allows you to scale your data processing in a customised way, with S3 serving as your storage. This enables the efficient processing of large amounts of data in batches and is again cost-effective, as you only pay for the clusters being processed. You can choose between temporary clusters for infrequent data processing or persistent clusters that continue running even after data processing is complete.
Data Analytic Services
Once your data is processed and structured, it’s ready for further analysis. Amazon Athena is a serverless service that helps to processes your data using SQL, without relying on clusters. Athena integrates seamlessly with Amazon S3, allowing for direct data processing without the need for data movement.
Other AWS services that work well with S3 include Amazon Redshift (data warehouse), which is similar to Athena but is more suited to pre-stored data. For real-time data processing, Amazon Kinesis Firehose can be used, with Amazon Data Analytics creating reports to highlight anomalies and trends in real-time data.
Amazon Elasticsearch / OpenSearch
Amazon Elasticsearch, this days known renamed to OpenSearch is a service that helps you locate specific pieces of data, whether it’s text, video, structured, or unstructured. Supported by S3, this service makes finding data stored in your data lake a breeze. Amazon ES includes Kibana, a service that helps visualise your data after it has been analysed, making it more discoverable.
Machine Learning Services
Machine learning is an emerging field that utilises artificial intelligence, especially useful for predicting future business outcomes. Many businesses use machine learning to gain a competitive advantage and save money, provided the predictions are accurate. It is crucial to select a reliable data to minimise risks associated with incorrect predictions.
AWS offers a range of machine learning services, such as Amazon SageMaker, which allows you to build, train, and deploy machine learning models easily. Additionally, AWS provides pre-trained AI services, like Amazon Rekognition for image and video analysis, and Amazon Comprehend for natural language processing. These services enable businesses to harness the power of machine learning to gain valuable insights and make data-driven decisions.
Summary
AWS provides a comprehensive suite of services designed to meet the diverse needs of businesses and individuals managing data lakes. These services cover data storage and organisation, data movement, processing, analytics, and machine learning. Key AWS services include Amazon S3 for storage, AWS Glue for data organisation, Kinesis family for real-time data movement, AWS EMR for batch processing, Amazon Athena and Redshift for analytics, Amazon Elasticsearch for data discovery, and Amazon QuickSight for dashboarding. The flexibility and interoperability of these services make AWS an ideal solution for those looking to store, process, and gain insights from their data. The choice of service depends on your specific use case. By leveraging the right combination of AWS services, users can effectively manage and make the most of their data in today’s data-driven world.
We have not covered all data lake related services, as AWS releases many new features on a regular basis that can help to expand data lake capabilities. One of the recent additions is Amazon MWAA, a managed Apache Airflow tool that provides advanced batch processing capabilities. That being said AWS is not by all means the ultimate end for data platforms’ needs. There is a richness of products from competing vendors that can do a better job in certain scenarios than native AWS services. Large enterprises often select to combine their AWS data cloud platform with products like SnowFlake which is a powerful data warehousing solution, Tableau for dashboarding and visualisation, Matilion for simplified and effective ETL, and Atlan which offers AI-aided data catalogue capability and which is combined with AI, last but not least Dataiku for AI aided machine learning. Usually, those services come with a premium price tag compared to AWS.
Additionally, other general cloud providers like Google Cloud Platform and Microsoft Azure are competing for the crown of best data management platforms. While Databricks focuses solely on data solutions.
Stay tuned to learn more about data platforms, you can follow the @DataPhoenix LinkedIn page.
As always, for any data platform needs, contact us at info@dataphoenix.io – a small end-to-end data solutions provider.
DataPhoenix team